Reactor的响应式流是如何工作的?
Reactor入门篇在这
# Reactor库的Cold和Hot有什么区别?
Cold序列:当订阅者开始订阅时,数据就开始流动。这意味着每个订阅者都将获得完整的数据元素。例如,如果你有一个返回数据库查询结果的Flux,每个订阅者都会得到完整的查询结果。Cold是最常用的序列类型。
Flux.just(),Flux.fromArray(),Flux.range(),Flux.fromIterable()等默认产生Cold序列Hot序列:与Cold序列不同,Hot序列在创建时就开始发布数据。无论是否有订阅者订阅,数据都会持续流动。这意味着如果订阅者在数据开始流动后订阅,那么他们可能会错过一些数据元素。这种序列在处理实时数据或者处理需要多个订阅者共享数据的场景下常见。
Sinks.Many或 ConnectableFlux,比如
Flux.publish(),Flux.replay()等产生Hot序列。Flux<Object hotFlux = // create 创建一个Cold序列,当有订阅者时才开始发布 ConnectableFlux.create(fluxSink - { while(true) { fluxSink.next(System.currentTimeMillis()); } }) // publish会把Flux转换为ConnectableFlux,订阅者将从当前数据流中的那一刻开始接收数据,而不是从数据源开始。这就是所谓的"hot"流。 注意:这个ConnectableFlux不会在被订阅时立刻开始发出数据,而是需要调用一次connect()方法才会开始。 .publish() // refCount可以自动管理数据流的生命周期。他会返回一个常规的Flux,会在第一次被订阅时立刻开始发出数据,当所有订阅者都取消订阅时自动停止发布数据。 .refCount();1
2
3
4
5
6
7
8
9
10
11Sinks.Many接口用于创建和处理Hot序列,他相比publish()这类操作符更加直观、清晰、易用。
Sinks.Many<String sink = Sinks.many() // 等效于Flu.publish() .multicast() // 遇到背压时缓存未被订阅者处理的元素 .onBackpressureBuffer(); Flux<String hotFlux = sink.asFlux(); // 非阻塞的发送数据 sink.tryEmitNext("item");1
2
3
4
5
6
7
8
9
10
# 操作符链是如何工作的?
当你调用操作符时,它并不会立刻执行操作,而是会返回一个新的Flux,这个新的Flux持有上一个Flux的引用。
Integer[] a = {1, 2};
Flux<Integer> map = Flux.fromArray(a)
.map(i -> i * 10)
.filter(i-> i % 10 == 0 );
map.subscribe(System.out::println);
2
3
4
5
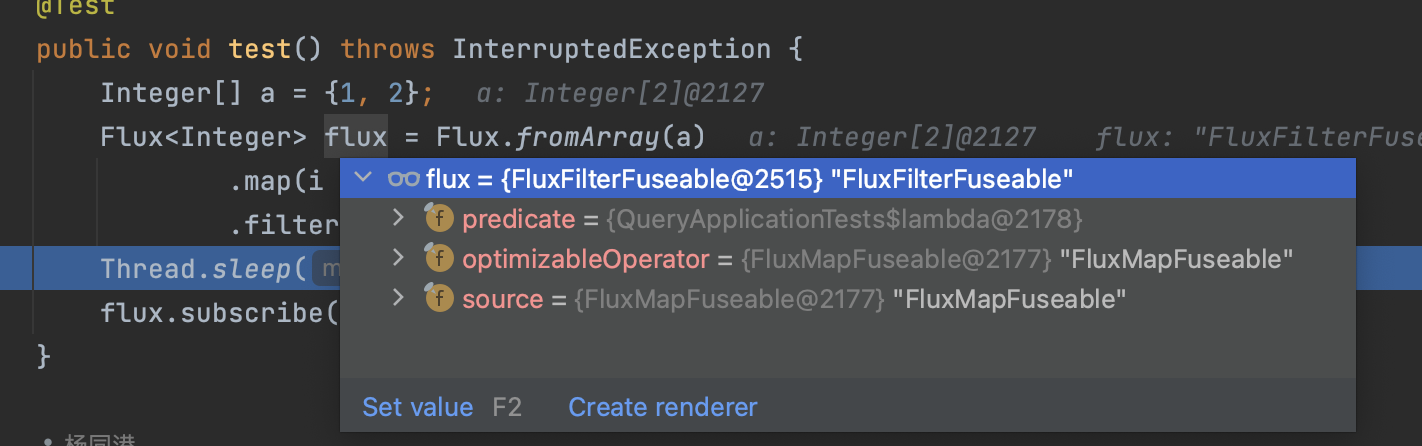
在这个示例中,filter()操作符接收一个函数i-> i % 10 == 0作为参数。filter()操作符返回一个新的FluxFilterFuseable类型的Flux,操作符中接收的这个Predicat类型的参数会被作为成员变量持有,同时它还会持有上级操作符optimizableOperator的引用,在这个demo中,他的上级操作符是map方法返回的FluxMapFuseable。
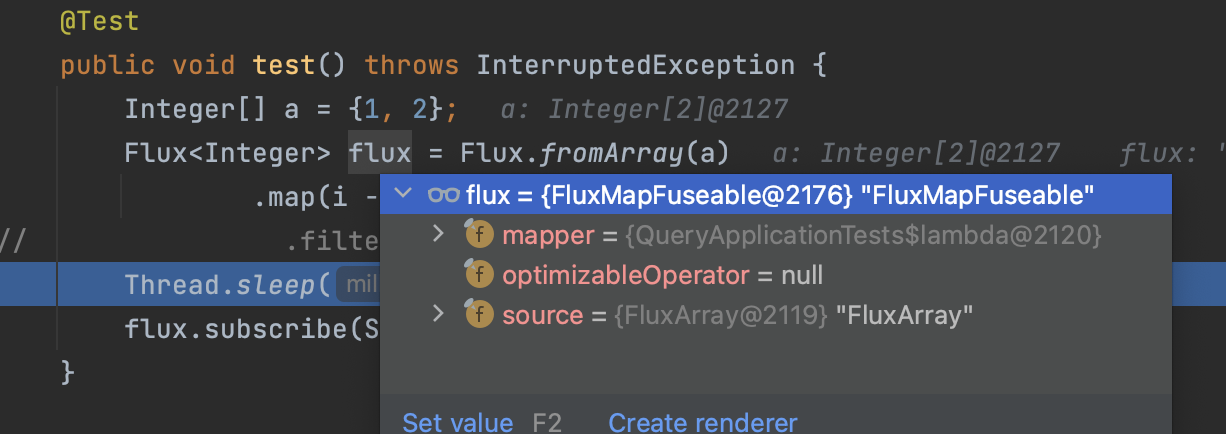
下图是map操作符的结构,因为他的上级就是源头,所以它的optimizableOperator是null。
这个新的FluxFilterFuseable类型的Flux在被订阅时会对它持有的那个上层操作符传递下来的每个元素应用这个函数。
当执行subscribe()时,传递的subscriber也会被层层包装
看到这,你应该对Flux的操作符链有了一个大概的模型。
class Operator{ Hook 操作符中的hook方法, map操作符时Function,filter是Predicat ...; Operator 上游操作符; Source 源头Flux; }1
2
3
4
5
# 数据流是如何向下游传递的?
在Reactor框架中,数据流的传递遵循了Reactive Streams规范中定义的"发布者/订阅者"模型。在这个模型中,Flux或Mono(发布者)会生成数据,并将数据传递给订阅者(Subscriber)。传递过程如下:
订阅者开始订阅发布者时,会调用发布者的
subscribe()方法,并将自己作为参数传入。这个方法调用会沿着操作符链条向上游传递,直到到达源头的发布者(也就是最初创建的那个Flux或Mono)。这是一个递归的过程,每个操作符在处理subscribe()方法调用时,都会先调用上游发布者的subscribe()方法。// Flux的subscribe方法 public final void subscribe(Subscriber<? super T> actual) { CorePublisher publisher = Operators.onLastAssembly(this); CoreSubscriber subscriber = Operators.toCoreSubscriber(actual); if (subscriber instanceof Fuseable.QueueSubscription && this != publisher && this instanceof Fuseable && !(publisher instanceof Fuseable)) { subscriber = new FluxHide.SuppressFuseableSubscriber<>(subscriber); } try { if (publisher instanceof OptimizableOperator) { OptimizableOperator operator = (OptimizableOperator) publisher; // 1. 开始递归订阅 while (true) { // 2. 向上游的操作符订阅。 当跳出递归时,操作符链上的所有操作符链已经全部被订阅。 subscriber = operator.subscribeOrReturn(subscriber); if (subscriber == null) { // null means "I will subscribe myself", returning... return; } OptimizableOperator newSource = operator.nextOptimizableSource(); // 4. 当没有上游操作符时,跳出递归。 if (newSource == null) { publisher = operator.source(); break; } //3. 寻找上游操作符, 如果有上游操作符就继续递归 operator = newSource; } } // 5. 订阅到源头 publisher.subscribe(subscriber); } catch (Throwable e) { Operators.reportThrowInSubscribe(subscriber, e); return; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40在 第 2 步中构造的subscriber结构类似Operator是嵌套自持有的, 订阅到最上游之后,最内部的subscriber是实际的消费者, 然后从内到外是操作符链下游到上游的subscriber,他的结构是这样的。
class SubScriber{ SubScriber 下游操作符的subscriber; Hook 此subscriber中订阅到的Operator中的的hook方法, map操作符时Function,filter是Predicat ...; }1
2
3
4在
subscribe()方法被调用后,发布者会创建一个Subscription,并将这个Subscription传递给订阅者的onSubscribe()方法。这个Subscription代表了订阅者和发布者之间的连接。订阅者收到
Subscription后调用Subscription的request()方法来向发布者请求数据。这是一种反向控制流,允许订阅者根据自己的能力来控制接收数据的速率。当
request()通过操作符链到达最上游的源头发布者时,发布者会调用Subscriber的onNext()方法,并将数据项作为参数传入,而Subscriber是自持有的,所以他会层层递归, 调用下游操作符的Subscriber的onNext()方法。这就是数据从发布者传递到订阅者的方式。// 这是filter操作符的subscriber的onNext方法 @Override public void onNext(T t) { if (sourceMode == ASYNC) { actual.onNext(null); } else { if (done) { Operators.onNextDropped(t, this.ctx); return; } boolean b; try { b = predicate.test(t); } catch (Throwable e) { Throwable e_ = Operators.onNextError(t, e, this.ctx, s); if (e_ != null) { onError(e_); } else { s.request(1); } Operators.onDiscard(t, this.ctx); return; } if (b) { // 调用持有的下游操作符的onNext actual.onNext(t); } else { s.request(1); Operators.onDiscard(t, this.ctx); } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37如果数据流正常结束(例如,Flux中的所有元素都已经被处理),发布者会调用
Subscriber的onComplete()方法。如果在处理数据流的过程中出现错误,发布者会调用订阅者的onError()方法,并将错误信息作为参数传入。
# subscribeOn和publishOn操作符是如何工作的?
在Reactor中,subscribeOn()和publishOn()是两个非常重要的调度器操作符,它们能够控制Flux或Mono的执行上下文,这对于处理阻塞或耗时的操作尤其有用。
subscribeOn(Scheduler scheduler)操作符会影响源Flux或Mono以及它上游的所有操作符的执行上下文。无论它在链路的何处被调用,它都会影响源头的执行上下文。换句话说,subscribeOn()定义了订阅的发生的调度器。比如,你可以将源数据的生成操作放在一个独立的线程或线程池中执行。
Flux.just("a", "b", "c")
.map(item -> doSomeWork(item)) // 这个方法可能会阻塞
.subscribeOn(Schedulers.boundedElastic()) // 将整个流的处理操作放到一个名为boundedElastic的调度器上
.subscribe(System.out::println);
2
3
4
publishOn(Scheduler scheduler)操作符则会影响它下游的所有操作符的执行上下文。这意味着在publishOn()之后的所有操作符都会在指定的调度器上执行。通常,我们会使用publishOn()来指定一些阻塞操作的执行上下文,以避免阻塞其他非阻塞操作。
Flux.just("a", "b", "c")
.publishOn(Schedulers.boundedElastic()) // 将后续的操作放到一个名为boundedElastic的调度器上
.map(item -> doSomeWork(item)) // 这个方法可能会阻塞
.subscribe(System.out::println);
2
3
4
5
结合上面数据流是如何向下游传递的已经明白了。
订阅是沿着操作符链从下向上走的,所以当遇到subscribeOn操作符时,会改变subscribeOn操作符之上的所有操作符以及源头的执行上下文
而发布是从上到下的,所以当遇到publishOn操作符,会改变publishOn操作符之下的所有操作符以及实际消费者所在上下文
完毕